Oxidizing sourmash: Python and FFI
I think the first time I heard about Rust was because Frank Mcsherry chose it to write a timely dataflow implementation. Since then it started showing more and more in my news sources, leading to Armin Ronacher publishing a post in the Sentry blog last November about writing Python extensions in Rust.
Last December I decided to give it a run:
I spent some time porting the C++ bits of sourmash
to Rust.
The main advantage here is that it's a problem I know well,
so I know what the code is supposed to do and can focus on figuring out
syntax and the mental model for the language.
I started digging into the symbolic codebase and understanding what they did,
and tried to mirror or improve it for my use cases.
(About the post title: The process of converting a codebase to Rust is referred as "Oxidation" in the Rust community, following the codename Mozilla chose for the process of integrating Rust components into the Firefox codebase. 1 Many of these components were tested and derived in Servo, an experimental browser engine written in Rust, and are being integrated into Gecko, the current browser engine (mostly written in C++).)
Why Rust?
There are other programming languages more focused on scientific software that could be used instead, like Julia2. Many programming languages start from a specific niche (like R and statistics, or Maple and mathematics) and grow into larger languages over time. While Rust goal is not to be a scientific language, its focus on being a general purpose language allows a phenomenon similar to what happened with Python, where people from many areas pushed the language in different directions (system scripting, web development, numerical programming...) allowing developers to combine all these things in their systems.
But by far my interest in Rust is for the many best practices it brings to the default experience: integrated package management (with Cargo), documentation (with rustdoc), testing and benchmarking. It's understandable that older languages like C/C++ need more effort to support some of these features (like modules and an unified build system), since they are designed by standard and need to keep backward compatibility with codebases that already exist. Nonetheless, the lack of features increase the effort needed to have good software engineering practices, since you need to choose a solution that might not be compatible with other similar but slightly different options, leading to fragmentation and increasing the impedance to use these features.
Another big reason is that Rust doesn't aim to completely replace what already exists, but complement and extend it. Two very good talks about how to do this, one by Ashley Williams, another by E. Dunham.
Converting from a C++ extension to Rust
The current implementation of the core data structures in sourmash is in a C++ extension wrapped with Cython. My main goals for converting the code are:
-
support additional languages and platforms. sourmash is available as a Python package and CLI, but we have R users in the lab that would benefit from having an R package, and ideally we wouldn't need to rewrite the software every time we want to support a new language.
-
reducing the number of wheel packages necessary (one for each OS/platform).
-
in the long run, use the Rust memory management concepts (lifetimes, borrowing) to increase parallelism in the code.
Many of these goals are attainable with our current C++ codebase, and
"rewrite in a new language" is rarely the best way to solve a problem.
But the reduced burden in maintenance due to better tooling,
on top of features that would require careful planning to execute
(increasing the parallelism without data races) while maintaining compatibility
with the current codebase are promising enough to justify this experiment.
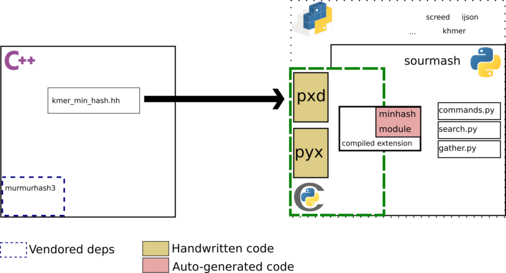
Cython provides a nice gradual path to migrate code from Python to C++, since it is a superset of the Python syntax. It also provides low overhead for many C++ features, especially the STL containers, with makes it easier to map C++ features to the Python equivalent. For research software this also lead to faster exploration of solutions before having to commit to lower level code, but without a good process it might also lead to code never crossing into the C++ layer and being stuck in the Cython layer. This doesn't make any difference for a Python user, but it becomes harder from users from other languages to benefit from this code (since your language would need some kind of support to calling Python code, which is not as readily available as calling C code).
Depending on the requirements, a downside is that Cython is tied to the CPython API, so generating the extension requires a development environment set up with the appropriate headers and compiler. This also makes the extension specific to a Python version: while this is not a problem for source distributions, generating wheels lead to one wheel for each OS and Python version supported.
The new implementation
This is the overall architecture of the Rust implementation:
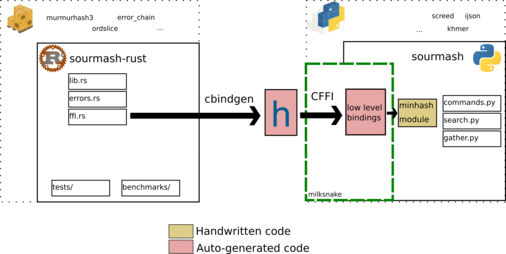 It is pretty close to what
It is pretty close to what symbolic does,
so let's walk through it.
The Rust code
If you take a look at my Rust code, you will see it is very... C++. A lot of the
code is very similar to the original implementation, which is both a curse and a
blessing: I'm pretty sure that are more idiomatic and performant ways of doing
things, but most of the time I could lean on my current mental model for C++ to
translate code. The biggest exception was the merge function, were I was doing
something on the C++ implementation that the borrow checker didn't like.
Eventually I found it was because it couldn't keep track of the lifetime
correctly and putting braces around it fixed the problem,
which was both an epiphany and a WTF moment. Here is an example that triggers
the problem, and the solution.
"Fighting the borrow checker" seems to be a common theme while learning Rust, but the compiler really tries to help you to understand what is happening and (most times) how to fix it. A lot of people grow to hate the borrow checker, but I see it more as a 'eat your vegetables' situation: you might not like it at first, but it's better in the long run. Even though I don't have a big codebase in Rust yet, it keeps you from doing things that will come back to bite you hard later.
Generating C headers for Rust code: cbindgen
With the Rust library working, the next step was taking the Rust code and generate C headers describing the
functions and structs we expose with the #[no_mangle] attribute in Rust
(these are defined in the ffi.rs module in sourmash-rust).
This attribute tells the Rust compiler to generate names that are compatible
with the C ABI, and so can be called from other languages that implement FFI
mechanisms. FFI (the foreign function interface) is quite low-level,
and pretty much defines things that C can represent: integers, floats, pointers
and structs. It doesn't support higher level concepts like objects or generics,
so in a sense it looks like a feature funnel.
This might sound bad, but ends up being something that other languages can
understand without needing too much extra functionality in their runtimes,
which means that most languages have support to calling code through an FFI.
Writing the C header by hand is possible, but is very error prone.
A better solution is to use cbindgen,
a program that takes Rust code and generate a C header file automatically.
cbindgen is developed primarily to generate the C headers for webrender,
the GPU-based renderer for servo,
so it's pretty likely that if it can handle a complex codebase it will work
just fine for the majority of projects.
Interfacing with Python: CFFI and Milksnake
Once we have the C headers, we can use the FFI to
call Rust code in Python. Python has a FFI module in the standard library: ctypes,
but the Pypy developers also created CFFI, which has more features.
The C headers generated by cbindgen can be interpreted by CFFI to generate
a low-level Python interface for the code. This is the equivalent of declaring
the functions/methods and structs/classes in a pxd file (in the Cython
world): while the code is now usable in Python, it is not well adapted to
the features and idioms available in the language.
Milksnake is the package developed by Sentry that takes care of running cargo
for the Rust compilation and generating the CFFI boilerplate,
making it easy to load the low-level CFFI bindings in Python.
With this low-level binding available we can now write something more Pythonic
(the pyx file in Cython), and I ended up just renaming the _minhash.pyx file
back to minhash.py and doing one-line fixes to replace the Cython-style code
with the equivalent CFFI calls.
All of these changes should be transparent to the Python code, and to guarantee that I made sure that all the current tests that we have (both for the Python module and the command line interface) are still working after the changes. It also led to finding some quirks in the implementation, and even improvements in the current C++ code (because we were moving a lot of data from C++ to Python).
Where I see this going
It seems it worked as an experiment, and I presented a poster at GCCBOSC 2018 and SciPy 2018 that was met with excitement by many people. Knowing that it is possible, I want to reiterate some points why Rust is pretty exciting for bioinformatics and science in general.
Bioinformatics as libraries (and command line tools too!)
Bioinformatics is an umbrella term for many different methods, depending on what analysis you want to do with your data (or model). In this sense, it's distinct from other scientific areas where it is possible to rely on a common set of libraries (numpy in linear algebra, for example), since a library supporting many disjoint methods tend to grow too big and hard to maintain.
The environment also tends to be very diverse, with different languages being used to implement the software. Because it is hard to interoperate, the methods tend to be implemented in command line programs that are stitched together in pipelines, a workflow describing how to connect the input and output of many different tools to generate results. Because the basic unit is a command-line tool, pipelines tend to rely on standard operating system abstractions like files and pipes to make the tools communicate with each other. But since tools might have input requirements distinct from what the previous tool provides, many times it is necessary to do format conversion or other adaptations to make the pipeline work.
Using tools as blackboxes, controllable through specific parameters at the command-line level, make exploratory analysis and algorithm reuse harder: if something needs to be investigated the user needs to resort to perturbations of the parameters or the input data, without access to the more feature-rich and meaningful abstraction happening inside the tool.
Even if many languages are used for writing the software, most of the time there is some part written in C or C++ for performance reasons, and these tend to be the core data structures of the computational method. Because it is not easy to package your C/C++ code in a way that other people can readily use it, most of this code is reinvented over and over again, or is copy and pasted into codebases and start diverging over time. Rust helps solve this problem with the integrated package management, and due to the FFI it can also be reused inside other programs written in other languages.
sourmash is not going to be Rust-only and abandon Python, and it would be crazy to do so when it has so many great exploratory tools for scientific discovery. But now we can also use our method in other languages and environment, instead of having our code stuck in one language.
Don't rewrite it all!
I could have gone all the way and rewrite sourmash in Rust3, but it would be incredibly disruptive for
the current sourmash users and it would take way longer to pull off. Because
Rust is so focused in supporting existing code, you can do a slow transition and
reuse what you already have while moving into more and more Rust code.
A great example is this one-day effort by Rob Patro to bring CQF (a C
codebase) into Rust, using bindgen (a generator of C bindings for Rust).
Check the Twitter thread for more =]
Good scientific citizens
There is another MinHash implementation already written in Rust, finch.
Early in my experiment I got an email from them asking if I wanted to work
together, but since I wanted to learn the language I kept doing my thing. (They
were totally cool with this, by the way). But the fun thing is that Rust has a
pair of traits called From and Into that you can implement for your
type, and so I did that and now we can have interoperable
implementations. This synergy allows finch to use sourmash methods,
and vice versa.
Maybe this sounds like a small thing, but I think it is really exciting. We can stop having incompatible but very similar methods, and instead all benefit from each other advances in a way that is supported by the language.
Next time!
Turns out Rust supports WebAssembly as a target, so... what if we run sourmash in the browser? That's what I'm covering in the next blog post, so stay tuned =]
Comments?
Footnotes
The creator of the language is known to keep making up different explanations for the name of the language, but in this case "oxidation" refers to the chemical process that creates rust, and rust is the closest thing to metal (metal being the hardware). There are many terrible puns in the Rust community. ↩
Even more now that it hit 1.0, it is a really nice language ↩
and risk being kicked out of the lab =P ↩